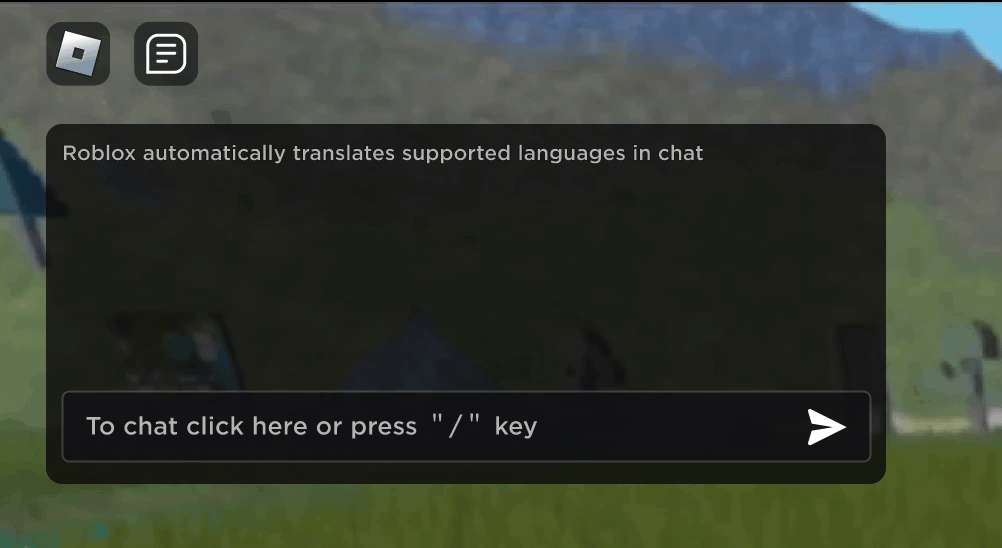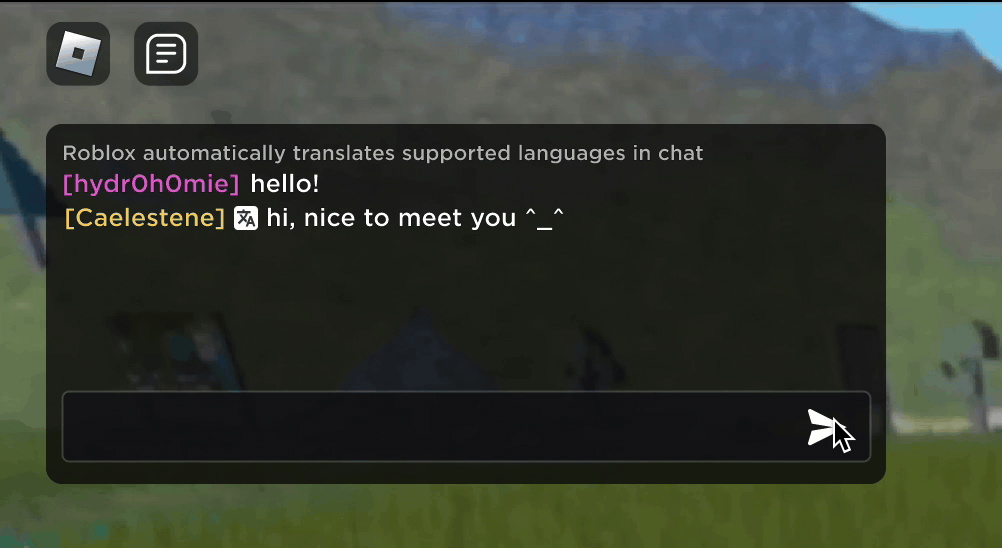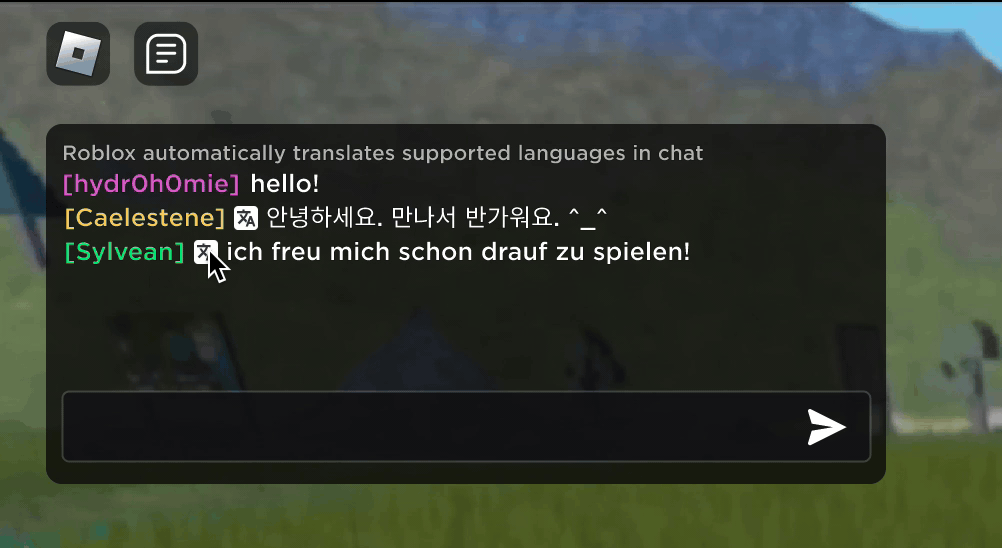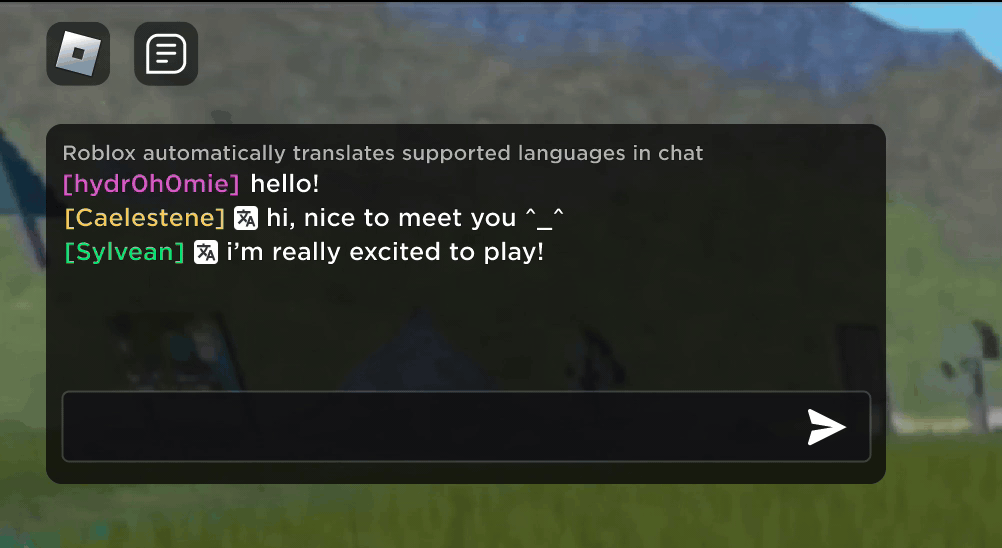
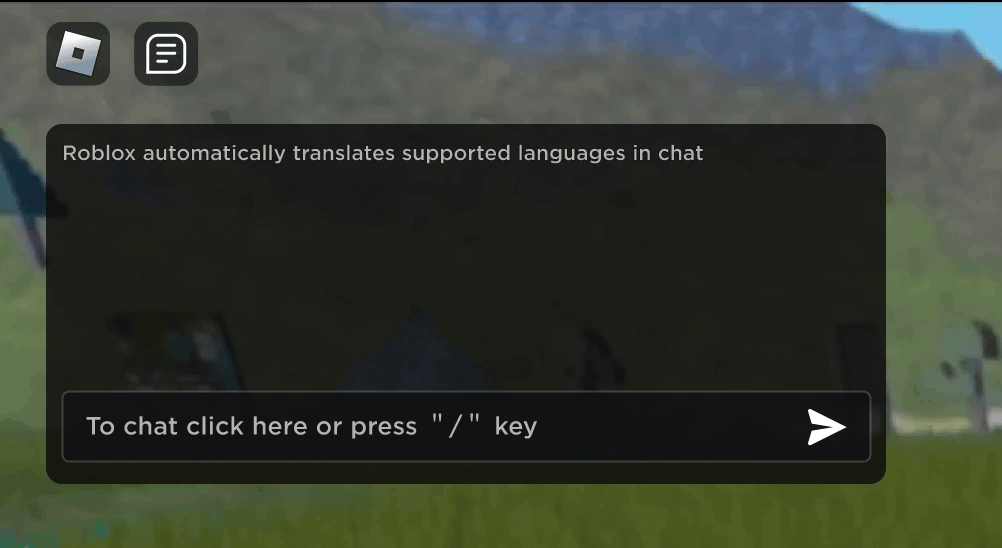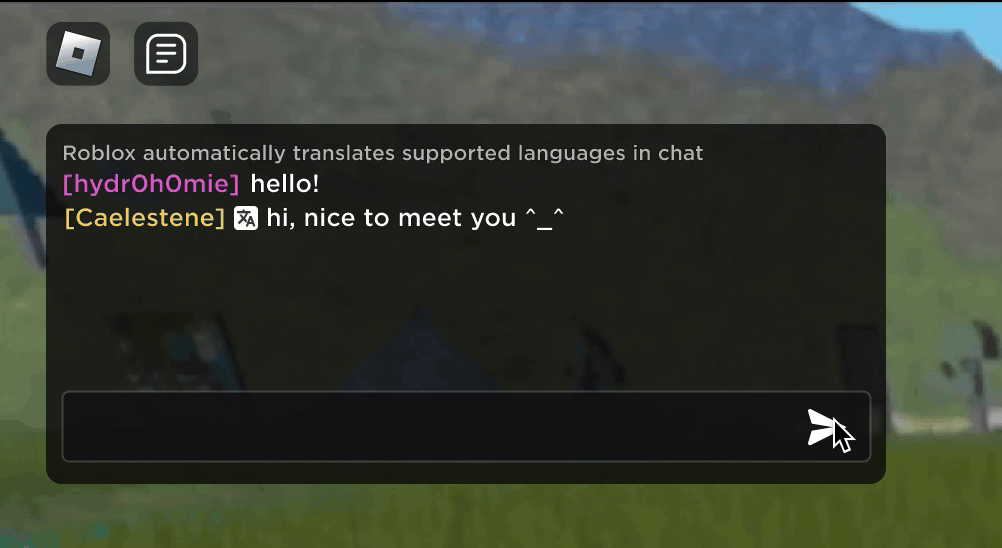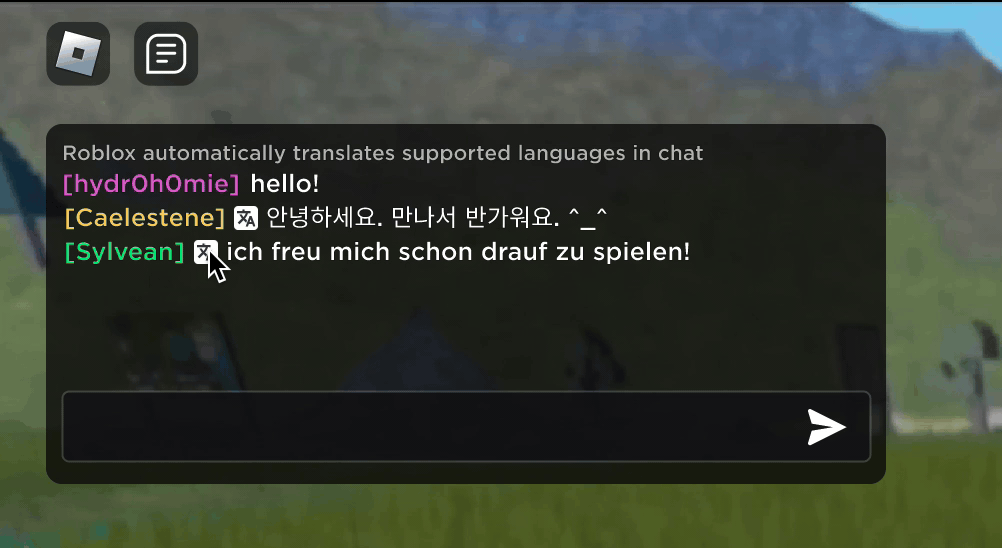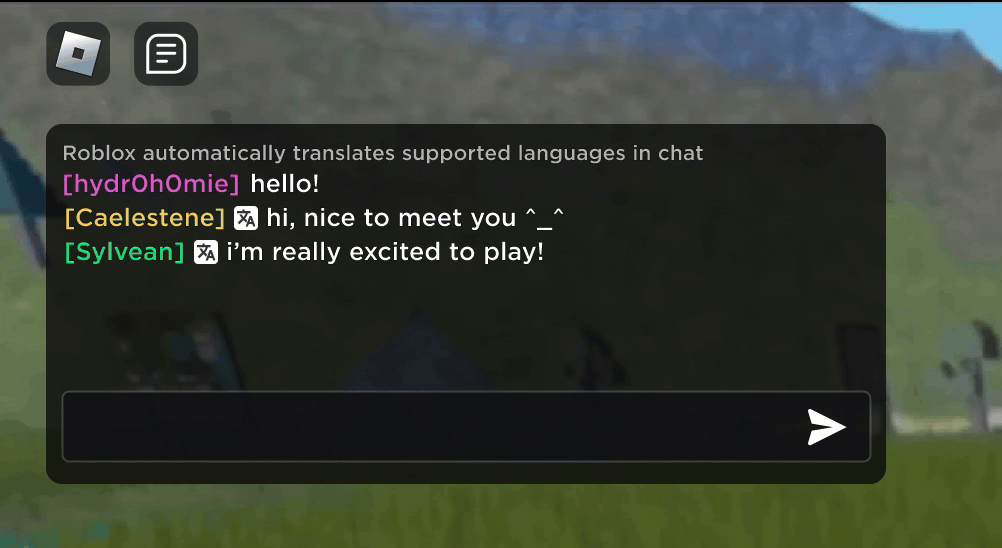
Imagine discovering that your new Roblox friend, a person you’ve been chatting and joking with in a new experience, is actually in Korea — and has been typing in Korean the entire time, while you’ve been typing in English, without either of you noticing. Thanks to our new real-time AI chat translations, we’ve made possible on Roblox something that isn’t even possible in the physical world — enabling people who speak different languages to communicate seamlessly with one another in our immersive 3D experiences. This is possible because of our custom multilingual model, which now enables direct translation between any combination of the 16 languages we currently support (these 15 languages, as well as English).
In any experience that has enabled our in-experience text chat service, people from different countries can now be understood by people who don’t speak their language. The chat window will automatically show Korean translated into English, or Turkish translated into German, and vice versa, so that each person sees the conversation in their own tongue. These translations are displayed in real time, with latency of approximately 100 milliseconds, so the translation happening behind the scenes is nearly invisible. Using AI to automate real-time translations in text chat removes language barriers and brings more people together, no matter where they live in the world.
Building a Unified Translation Model
AI translation is not new, the majority of our in-experience content is already automatically translated. We wanted to go beyond translating static content in experiences. We wanted to automatically translate interactions — and we wanted to do that for all 16 languages we support on the platform. This was an audacious goal for two reasons: First, we weren’t just translating from one primary language (i.e., English) to another, we wanted a system capable of translating between any combination of the 16 languages we support. Second, it had to be fast. Fast enough to support real chat conversations, which to us meant getting latency down to approximately 100 milliseconds.
Roblox is home to more than 70 million daily active users all over the world and growing. People are communicating and creating on our platform — each in their native language — 24 hours a day. Manually translating every conversation happening across more than 15 million active experiences, all in real time, is obviously not feasible. Scaling these live translations to millions of people, all having different conversations in different experiences simultaneously, requires an LLM with tremendous speed and accuracy. We need a context-aware model that recognizes Roblox-specific language, including slang and abbreviations (think obby, afk, or lol). Beyond all of that, our model needs to support any combination of the 16 languages Roblox currently supports.
To achieve this, we could have built out a unique model for each language pair (i.e., Japanese and Spanish), but that would have required 16×16, or 256 different models. Instead, we built a unified, transformer-based translation LLM to handle all language pairs in a single model. This is like having multiple translation apps, each specializing in a group of similar languages, all available with a single interface. Given a source sentence and target language, we can activate the relevant “expert” to generate the translations.
This architecture allows for better utilization of resources, since each expert has a different specialty, which leads to more efficient training and inference — without sacrificing translation quality.

Illustration of the inference process. Source messages, along with the source language and target languages are passed through RCC. Before hitting the back end, we first check cache to see if we already have translations for this request. If not, the request is passed to the back end and to the model server with dynamic batching. We added an embedding cache layer between the encoders and decoders to further improve efficiency when translating into multiple target languages.
This architecture makes it far more efficient to train and maintain our model for a few reasons. First, our model is able to leverage linguistic similarities between languages. When all languages are trained together, languages that are similar, like Spanish and Portuguese, benefit from each other’s input during training, which helps improve the translation quality for both languages. We can also far more easily test and integrate new research and advances in LLMs into our system as they’re released, to benefit from the latest and greatest techniques available. We see another benefit of this unified model in cases where the source language is not set or is set incorrectly, where the model is accurate enough that it’s able to detect the correct source language and translate into the target language. In fact, even if the input has a mix of languages, the system is still able to detect and translate into the target language. In these cases, the accuracy may not be quite as high, but the final message will be reasonably understandable.
To train this unified model, we began by pretraining on available open source data, as well as our own in-experience translation data, human-labeled chat translation results, and common chat sentences and phrases. We also built our own translation evaluation metric and model to measure translation quality. Most off-the-shelf translation quality metrics compare the AI translation result to some ground truth or reference translation and focus primarily on the understandability of the translation. We wanted to assess the quality of the translation — without a ground truth translation.
We look at this from multiple aspects, including accuracy (whether there are any additions, omissions, or mistranslations), fluency (punctuation, spelling, and grammar), and incorrect references (discrepancies with the rest of the text). We classify these errors into severity levels: Is it a critical, major, or minor error? In order to assess quality, we built an ML model and trained it on human labeled error types and scores. We then fine-tuned a multilingual language model to predict word-level errors and types and calculate a score using our multidimensional criteria. This gives us a comprehensive understanding of the quality and types of errors occurring. In this way we can estimate translation quality and detect errors by using source text and machine translations, without requiring a ground truth translation. Using the results of this quality measure, we can further improve the quality of our translation model.

With source text and the machine translation result, we can estimate the quality of the machine translation without a reference translation, using our in-house translation quality estimation model. This model estimates the quality from different aspects and categorizes errors into critical, major, and minor errors.
Less common translation pairs (say, French to Thai), are challenging due to a lack of high quality data. To address this gap, we applied back translation, where content is translated back into the original language, then compared to the source text for accuracy. During the training process, we used iterative back translation, where we use a strategic mix of this back translated data and supervised (labeled) data to expand the amount of translation data for the model to learn on.

Illustration of the model training pipeline. Both parallel data and back translation data are used during the model training. After the teacher model is trained, we apply distillation and other serving optimization techniques to reduce the model size and improve the serving efficiency.
To help the model understand modern slang, we asked human evaluators to translate popular and trending terms for each language, and included those translations in our training data. We will continue to repeat this process regularly to keep the system up to date on the latest slang.
The resulting chat translation model has roughly 1 billion parameters. Running a translation through a model this large is prohibitively resource-intensive to serve at scale and would take much too long for a real-time conversation, where low latency is critical to support more than 5,000 chats per second. So we used this large translation model in a student-teacher approach to build a smaller, lighter weight model. We applied distillation, quantization, model compilation, and other serving optimizations to reduce the size of the model to fewer than 650 million parameters and improve the serving efficiency. In addition, we modified the API behind in-experience text chat to send both the original and the translated messages to the person’s device. This enables the recipient to see the message in their native language or quickly switch to see the sender’s original, non-translated message.
Once the final LLM was ready, we implemented a back end to connect with the model servers. This back end is where we apply additional chat translation logic and integrate the system with our usual trust and safety systems. This ensures translated text gets the same level of scrutiny as other text, in order to detect and block words or phrases that violate our policies. Safety and civility is at the forefront of everything we do at Roblox, so this was a very important piece of the puzzle.
Continuously Improving Accuracy
In testing, we’ve seen that this new translation system drives stronger engagement and session quality for the people on our platform. Based on our own metric, our model outperforms commercial translation APIs on Roblox content, indicating that we’ve successfully optimized for how people communicate on Roblox. We’re excited to see how this improves the experience for people on the platform, making it possible for them to play games, shop, collaborate, or just catch up with friends who speak a different language.
The ability for people to have seamless, natural conversations in their native languages brings us closer to our goal of connecting a billion people with optimism and civility.
To further improve the accuracy of our translations and to provide our model with better training data, we plan to roll out a tool to allow people on the platform to provide feedback on their translations and help the system improve even faster. This would enable someone to tell us when they see something that’s been mistranslated and even suggest a better translation we can add into the training data to further improve the model.
These translations are available today for all 16 languages we support — but we are far from done. We plan to continue to update our models with the latest translation examples from within our experiences as well as popular chat phrases and the latest slang phrases in every language we support. In addition, this architecture will make it possible to train the model on new languages with relatively low effort, as sufficient training data becomes available for those languages. Further out, we’re exploring ways to automatically translate everything in multiple dimensions: text on images, textures, 3D models, etc.
And we are already exploring exciting new frontiers, including automatic voice chat translations. Imagine a French speaker on Roblox being able to voice chat with someone who only speaks Russian. Both could speak to and understand one another, right down to the tone, rhythm, and emotion of their voice, in their own language, and at low latency. While this may sound like science fiction today, and it will take some time to achieve, we will continue to push forward on translation. In the not-too-distant future, Roblox will be a place where people from all around the world can seamlessly and effortlessly communicate not just via text chat, but in every possible modality!
The post Breaking Down Language Barriers with a Multilingual Translation Model appeared first on Roblox Blog.